



Compositional Sentence Embedding Using Deep Learning
- 0 Collaborators
Given a corpus of sentences, create a fixed length vector representation of each sentence which best represents the sentence in terms of semantic and syntactic correctness. Try both supervised (given class labels like sentiment as- sociated with each sentence/phrase ) and unsupervised( you just have a big document of sentences) methods. ...learn more
Project status: Under Development
Intel Technologies
AI DevCloud / Xeon,
Intel Opt ML/DL Framework,
Intel CPU
Overview / Usage
We have had good word embeddings which encode the notion of similarity. Our idea is to extend this to sen- tences by exploiting the compositionality of the sentence structure (the constituency/dependency parse tree). So far, the unsupervised ways of learning these embeddings dont make use of the recursive tree structure which cap- tures certain important semantic and syntactic informa- tion. Our main goal is to achieve the notion of similarity between these sentence representations, where word em- beddings have been quite successful. If we achieve this , we could use these embeddings for bigger tasks which need pre-trained representations for sentences. One real world example would be topics classification of ques- tions in Quora. They can directly use these sentence em- beddings to predict the topic. The complexity of the task is reduced. We propose novel architectures for both, su- pervised and unsupervised tasks.
Methodology / Approach
Knowledge Resources and Techniques Used
Supervised Tasks
Sentence Classification for the following data sets : MR,SST-1,SST-2,Subj,TREC,Irony,Opi,Tweet,Polite For the datasets in which we dont have the parse trees,
we plan to generate the parse trees using the Stanford Parser. We could also use the unsupervised methods which we are going to discuss.
Initial Word embeddings : One hot/ random initializa- tion/ Glove/Word2vec
We learn these embeddings along with the sentence embedding as part of the classification task.
Architecture 1
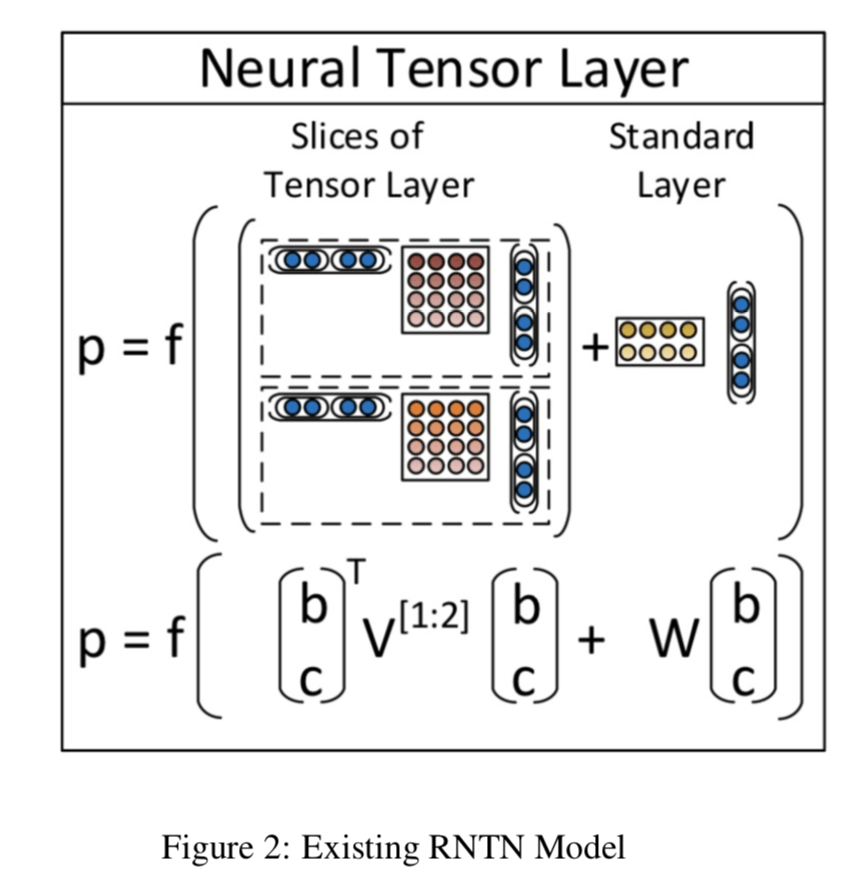
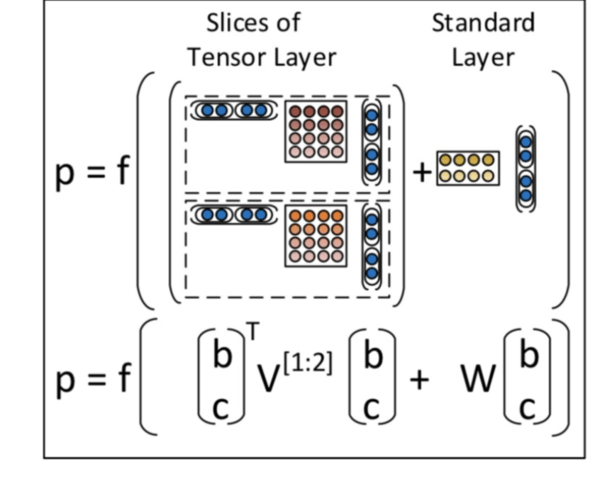
The data set provides the constituency parse tree for each sentence. So we have syntactic information at each node like VP,NP(verb phrase , noun phrase etc). The existing implementation of RNTN doesnt make use of this infor- mation. We plan to use different weights at each node based on this syntactic information. So the composition function for each node will have both tensors and these different weights. Since there are more parameters , it could take more time to train, but we feel it could deliver better results.
matrix(like the Tensor V) of N*(d2d weight matrices) where N is a known number of phrase types.
Architecture 2
TreeLSTM is a hierarchical recurrent neural network , it combine the concepts of recursive and recurrent neural networks.
We plan to incorporate the tensor concept used in RNTN to capture relationships between two children words in TreeLSTM. For example : In Recursive NN, not awesome is more positive than fairly awesome and not annoying has a similar shape as unbelievably annoy- ing. This would lead us to predict wrong sentiments. So this tensor feature of RNTN helps us to find these inter- actions among the children which could be really useful for our task. Even though the LSTM has hidden mem- ory and other gates , it might miss this information for certain difficult sentences.
TreeLSTM with Tensor/Matrix interaction between children. Lets assume we have a binary parse tree. (Stan- ford sentiment tree bank is binary) . For each node , we use information from the children.
Figure 2: Existing RNTN Model
In Figure 1, W is different for each syntactic category. Instead of having one common weight matrix , we have multiple weight matrices. W is d2d dimensions where d is the dimension of the word embeddings. We store a 3D
Hj prime which just sums the children nodes embed- dings, is modified as follows :
(H1,h2)Transpose * V[1:d] * (H1,h2) . This is also d dimensions. This is exactly the same tensor in RNTN.
For the input gate (i) , output gate (o) and update func- tion (u) , where hj prime is used , we use this new hj prime. It is common cross all gates.
2
We leave the forget gate as it is. It selectively forgets information from its children. But yes this could have an effect on the interaction between the children and while training we might not be able to optimize the parame- terrs. But we are willing to give it a try.
Architecture 3
The state of the art TreeGRU is similar to TreeLSTM, just uses different gates. It also has an attention mecha- nism. Since its a recursive model as well ,we could incor- porate tensors/ syntactic information as proposed in the above two architectures. We could also try bidirectional / deeper (extra hidden layers) architectures .
Unsupervised
We plan to use the concept of autoencoders to learn sen- tence embeddings. Its basically the same idea as of a neural translation model where the source and target lan- guage is same. The input and output is the same sen- tence.
The end to end model is trained with the cross entropy loss. We use softmax in the decoder to predict the out- puts.
LSTM encoder - LSTM decoder (different composi- tion loss function)
RNTN encoder - LSTM decoder
RNTN encoder - RNTN decoder ( we calculate the re- construction error at each node)( Use one weight matrix for encoding and one for decoding. In the ideal situation we want both to be inverse of each other, perfect sce- nario)
Possible alternatives : TreeLSTM/TreeGRU
After training we have the updated word embeddings and network parameters(encoders), so given a new sen- tence we can get the sentence embedding and use it for various purposes. We plan to keep paragraph vector
model as a baseline for this task.
CNN does not need parse trees and encodes vectors
for all kinds of phrases with the same words. Could be used for sentence classification as well. We also plan to explore attention mechanisms.
Some of these architectures can be used for other tasks like Paraphrase detection and Relation classification as well.
SemEval-2014 Task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness
We plan to visualize these word and sentence embed- dings in the 2d space using t-SNE and obtain clusters of semantically/ syntactically similar sentences. Also ana- lyze why two semantically different sentences are being clustered together.
Technologies Used
Python libraries - numpy, pandas, sklearn, tensorflow
on
Intel AI devCloud